搜索到
57
篇与
的结果
-
python访问Lua 安装环境:apt-get install liblua5.4-dev pip3 install lupaPython访问Lua虚拟机获取虚拟机:import lupa.lua54 as lupa from lupa import LuaRuntime lua = LuaRuntime(unpack_returned_tuples=True)访问Lua全局表:lua.globals()["print"] = print执行Lua代码1: lua.execute('print("hello")')执行Lua代码2: ret = lua.eval("_VERSION") , ret 是一个Lua变量封装变量判定Lua变量类型: lupa.lua_type封装变量给Lua访问:ret = lupa.as_itemgetter(py_dict) #Lua索引`ret`时优先取数据 ret = lupa.as_attrgetter(py_dict) #Lua索引`ret`时优先取属性方法Lua访问PythonLua脚本内置Python变量 python.builtinsuserdatapython内置类型,包含print/len/type/isinstance/list/dict等等python.argsfunctiontodopython.as_functionfunctiontodopython.evaluserdata用于执行python字符串代码python.set_overflow_handlerfunctiontodopython.noneuserdata类似lua中的nil, 遍历pyobj时可以直接相等判定python.enumeratefunction类似ipairs,遍历pyobj, 返回index和value。 但是index从0开始,如果是Dict则value其实是keypython.iterfunction遍历pyobj, 一次只返回一个值,list类型的元素值或者dict类型的key值python.as_itemgetterfunction设置pyobj数据在Lua索引时访问优先python.as_attrgetterfunction设置pyobj数据在Lua索引时属性方法优先索引python.iterexfunction类似pairs, 遍历pyobj, 返回key和value
-
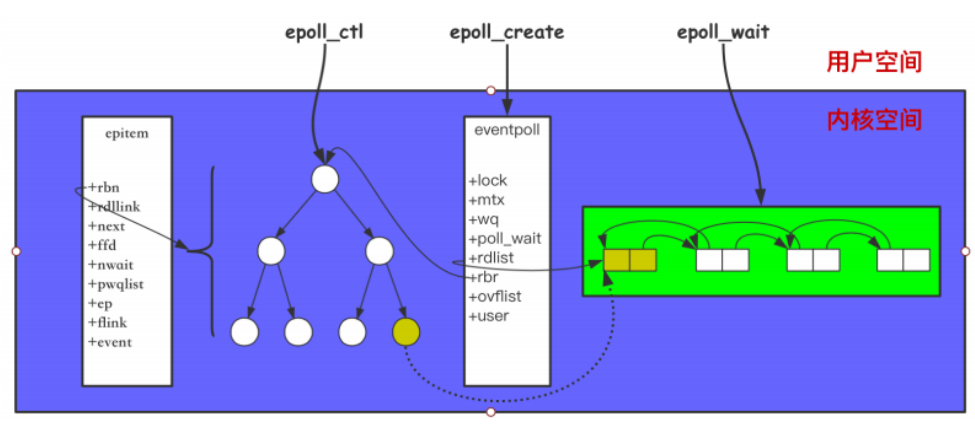
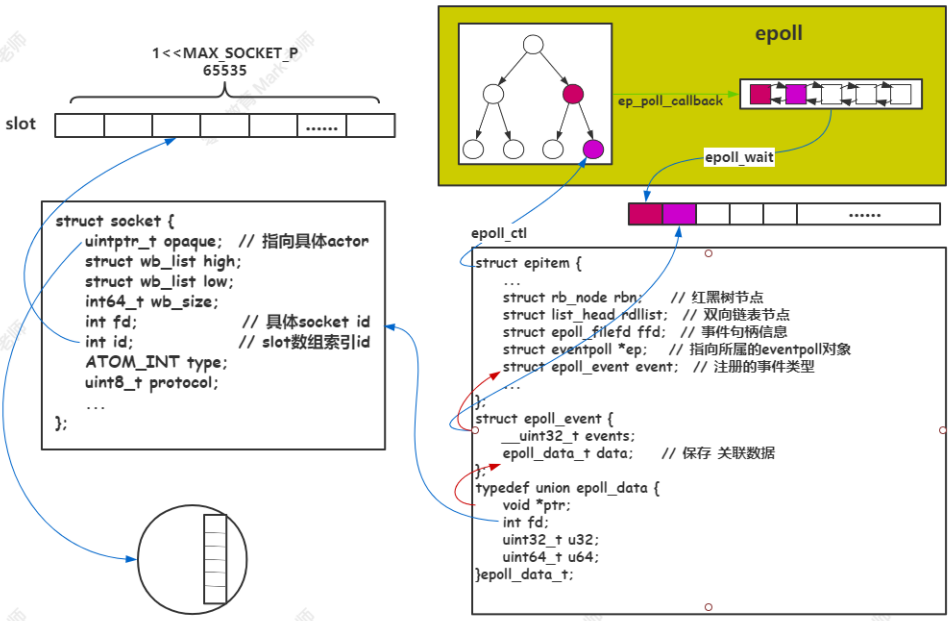
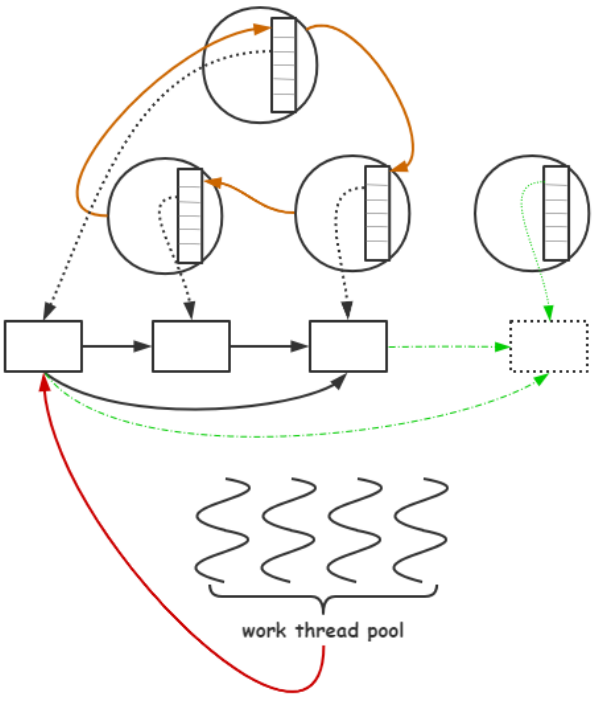
skynet原理 Skynet设计原理Skynet框架是属于一种多核并发编程模型,常见的多核并发模型有:多线程模型在一个进程中开启多线程,为了充分利用多核,一般设置工作线程的个数为 CPU的核心数;Memcached 就是采用这种方式;多线程在一个进程当中,所以数据共享来自进程当中的内存;这里会涉及到很多临界资源的访问,所以需要考虑加锁, 小粒度考虑使用自旋锁;多进程模型在一台机器当中,开启多个进程充分利用多核,一般设置工作进程的个数为 CPU的核心数;Nginx 就是采用这种方式;Nginx 当中的worker进程,通过共享内存来进行共享数据;也需要考虑使用锁;比如ngx_shmtx_t依次尝试使用自旋锁、信号量、文件锁。CSP模型CSP(Communicating Sequential Processes), 以 go 语言为代表,并发实体是协程(用户态线程、轻量级线程), 使用管道channel来通信;内部也是采用多少个核心开启多少个内核线程来充分利用多核;Actor模型Erlang 从语言层面支持 Actor 并发模型,并发实体是 Actor(在 Skynet中称之为服务),他们通过发送消息来相互通信;Skynet采用 C + Lua来实现 Actor 并发模型;底层也是通过采用多少个核心开启多少个内核线程来充分利用多核;总结 :不要通过共享内存来通信,而应该通过通信来共享内存;CSP 和 Actor 都符合这一哲学;通过通信来共享数据,其实是一种解耦合的过程;并发实体之间可以分别开发并进行单独优化,而它们唯一的耦合在于消息;这能让我们快速地进行开发;同时也符合我们开发的思路,将一个大的问题拆分成若干个小问题;Skynet框架主要就是Actor模块的封装。它是一个轻量级游戏服务器框架,而不仅仅用于游戏,还有金融、监控等;轻量级体现在:仅实现 actor 模型,以及相关的脚手架(工具集),如消息队列通信、调度、广播、资源共享等(lualib目录下的功能HTTP、Websocket、DB、Sharedata等也属于此列);实现了服务器框架的基础组件;实现了 reactor 并发网络库;并提供了大量连接的接入方案;基于自身网络库,实现了常用的数据库驱动(异步连接方案),并融合了Lua 数据结构;环境准备centos :yum install -y git gcc readline-devel autoconfubuntu :apt-get install git build-essential readline-dev autoconf # 或者 apt-get install git build-essential libreadline-dev autoconfMac:brew install git gcc readline autoconfActor模型有消息的 Actor 为活跃的 Actor,没有消息为非活跃的 Actor;Actor定义用于并行计算;可以理解为用户态轻量级进程。Actor 是最基本的计算单元和并发单元, 有自己的状态访谈变量和行为;基于消息计算,有自己的Mailbox消息队列、消息处理回调函数;Actor 通过消息进行沟通Actor的组成隔离的环境主要通过 Lua 虚拟机来实现;消息队列用来存放有序(先后到达)的消息;消息处理回调函数用来运行 Actor;从 Actor 的消息队列中取出消息,并作为该回调函数的参数来运行 Actor;Actor 创建skynet启动服务流程函数调用源码路径skynet.newservicelualib/skynet.luacommand.LAUNCHservice/launcher.lua (以下都在launcher服务中调用)skynet.launchlualib/skynet/manager.lualcommandlualib-src/lua-skynet.ccmd_launchskynet-src/skynet_server.cskynet_context_newskynet-src/skynet_server.cActor 底层关键接口// 对于snlua服务来说,用于创建隔离的环境 void * skynet_module_instance_create(struct skynet_module *m); // 用于设置初始回调函数和给自己发送初始化消息 int skynet_module_instance_init(struct skynet_module *m, void * inst, struct skynet_context *ctx, const char * parm); // 用于释放 Actor 对象 void skynet_module_instance_release(struct skynet_module *m, void *inst); // 用于处理 信号 消息,比如中断死循环 void skynet_module_instance_signal(struct skynet_module *m, void *inst, int signal);Actor 运行skynet.start会设置Actor消息回调函数,一个消息执行时会获取一个协程执行它。设置ctx->cb消息回调关键:函数源码路径skynet.startskynet.luac.callback(skynet.dispatch_message)skynet.lualcallbacklualib-src/lua-skynet.cskynet_callbackskynet-src/skynet_server.c一切从thread_worker函数开始运行,每个消息都会有一个协程来执行它。函数源码路径thread_workerskynet-src/skynet_start.cskynet_context_message_dispatchskynet-src/skynet_server.cskynet_mq_popskynet-src/skynet_mq.cdispatch_messageskynet-src/skynet_server.cctx->cbskynet-src/skynet_server.cskynet.dispatch_messageskynet.lua 以Lua消息为例skynet.raw_dispatch_messageskynet.luaco_createskynet.luaskynet.dispatch所注册的协程入口函数skynet.luaLua虚拟机有一个限制,同时只有一个协程在运行。所以写代码时以单线程思维方式在组织代码。内核线程取出消息队列,找到Lua虚拟机,从协程池取出一个协程来执行消息运行Actor 消息Actor 模型基于消息计算,在 Skynet 框架中,消息包含 Actor (之间)消息、网络消息以及定时消息;Actor 之间消息-- addr 对端服务的地址 -- typename 消息类型 actor内部间通常为 lua 类型消息 -- ... 为可变参 -- skynet.send是百分百会到达的, 异步消息,不等待对方反馈 skynet.send(addr, typename, ...) -- addr 对端服务的地址 -- typename 消息类型 actor内部间通常为 lua 类型消息 -- ... 为可变参 -- skynet.call就是发起一次远程调用,调用者会被挂起,等待对方回应后唤醒并处理返回值 -- 注意: -- 对端需要显示调用 skynet.ret(...) 回应 skynet.call 的请求 -- 或者通过调用 skynet.response() 延迟回应 skynet.call 的请求 skynet.call(addr, typename, ...)网络消息Skynet 当中采用一个 socket 线程来处理网络信息;Skynet 基于 reactor 网络模型;问题:网络当中获取数据,怎么知道FD数据传递到哪个服务(Actor)的消息队列当中去?// 在 linux 系统中,采用 epoll 来检测管理网络事件; int epoll_create(int size); int epoll_ctl(int epfd, int op, int fd, struct epoll_event* event); int epoll_wait(int epfd, struct epoll_event* events, int maxevents, int timeout); // epoll常见事件:EPOLLIN,EPOLLOUT,EPOLLHUP,EPOLLERR // 注意右边的就绪队列是事件队列,epoll_wait是从就绪队列中取事件通过epoll_ctl设置struct epoll_event中data.ptr = (struct socket *)ud;来完成fd与Actor绑定。有一个slot池,不和Redis一样用fd来创建大池。通过定义域相对较小的id创建预分配socket池。Lua层只能访问到slot idx来当作FDSkynet的Lua逻辑通过socket.start(fd, func)来完成Actor与FD的绑定定时消息定时器线程发送给Actor的消息。工作线程通过skynet_timeout函数调用 timer_add函数在时间轮加入新定时器。当时间到达时,在dispatch_list处理并调用skynet_context_push给工作线程压入超时消息。Skynet 采用多层级时间轮来解决多线程环境下定时任务的管理;时间复杂度为O(1) ;当定时任务被触发,将会向目标 Actor 发送定时消息,从而驱动 Actor 的运行;网络消息推送到 Actor函数源码备注skynet_socket_pollskynet-src/socket_server.csocket线程循环主要工作socket_server_pollskynet-src/socket_server.c处理外部客户端和内部管道数据forward_messageskynet-src/skynet_socket.c将消息推送到所属Actor消息队列ctrl_cmdskynet-src/socket_server.c处理work线程通过PIPE发送来数据sp_waitskynet-src/socket_epoll.h阻塞处理IO事件report_connectskynet-src/socket_server.c连接第三方服务 建立成功的标识report_acceptskynet-src/socket_server.c接收到客户端的连接,在这里可以绑定不同的client对应不同的服务forward_message_tcpskynet-src/socket_server.c读事件send_bufferskynet-src/socket_server.c写事件,把写缓存区发送出去Actor的调度工作线程流程全局单向队列和Actor消息队列都是先进先出,前者保证不饿死,后者保证顺序处理工作线程从全局队列中 pop 出单个 Actor 消息队列;从 Actor 消息队列中按照规则 pop 出一定数量的消息进行执行;若 Actor 消息队列中仍有消息继续放入全局队列队尾;若 Actor 消息队列中没有消息则不放入全局队列中;全局队列只存活跃的 Actor 消息队列;非活跃的Actor不在全局队列中。这个流程和Nginx线程池工作原理一致工作线程权重工作线程数量是按照 CPU 核心数来设置的;工作线程按照下面工作线程权重图来设置每个工作线程的权重;// 工作线程权重图,32核 static int weight[] = { -1, -1, -1, -1, 0, 0, 0, 0,// 前4个线程只消耗1个,后4个线程全部消耗 1, 1, 1, 1, 1, 1, 1, 1, // 一次消耗1/2个消息 2, 2, 2, 2, 2, 2, 2, 2, // 1/4 3, 3, 3, 3, 3, 3, 3, 3, }; // 1/8工作线程执行规则int i,n=1; for (i=0; i<n; i++) { // 注意: skynet_mq_pop pop出消息则返回0,没有pop消息返回1 if (skynet_mq_pop(q, &msg)) { skynet_context_release(ctx); return skynet_globalmq_pop(); } else if (i==0 && weight >= 0) {// 在执行第1次时就计算出本轮会分发几个消息 n = skynet_mq_length(q); n >>= weight;// n >> 0 = n , n >> 1 = n/2 } ... // 调用 actor 回调函数消费消息 dispatch_message(ctx, &msg); }从上面逻辑可以看出,当工作线程的权重为 -1 时,该工作线程每次只 pop 一条消息;当工作线程的权重为 0 时,该工作线程每次消费完所有的消息(防止消息多的Actor频繁线程切换);当工作线程的权重为 1 时,每次消费消息队列中 1/2的消息;当工作线程的权重为 2 时,每次消费消息队列中1/4 的消息;以此类推;通过这种方式,完成消息队列梯度消费,从而不至于让某些队列过长;这种消息调度的方式不是最优的调度方式(相较于 go 语言,Go可以绑定线程等),云风也在尝试修改更优的方式来调度;但是目前从多年线上实践情况来看,Skynet 运行良好;调度问题关注锁的使用,参考多核并发编程当中Nginx实现多个工作线程从全局消息队列中取次级消息队列,应该采用什么锁?自旋当 Skynet 全局消息队列节点很少的时候,怎么让多余的工作线程得到休眠?互斥+条件变量在问题 2 的基础上,如果此时全局消息队列节点很多后,怎么让休眠的工作线程得到唤醒?定时Skynet多个虚拟机共享函数原型、字符串等,实现一个虚拟机200KB左右内存。总体原理图关于并发和并行并行定义为一个时间点是有多个任务同时被处理。并发定义为一个时间段内多个任务被处理了。类似于一个CPU通过切换任务可以达到在一个时间段内处理多个队列。Skynet框架并发体现在:内部调度Actor时就是并发模型在socket数据分发使用的reactor模型多线程并行处理成千上万的Actor

-
文件bom头 有关于BOM,是Windows程序处理文本是常用,但linux不常用。BOM 是 byte-order mark 的缩写,是 "字节序标记" 的意思, 它常被用来当做标识文件是以 UTF-8、UTF-16 或 UTF-32编码的标记。在 Unicode 编码中有一个叫做 "零宽度非换行空格" 的字符 ( ZERO WIDTH NO-BREAK SPACE ), 用字符 FEFF 来表示对于 UTF-16 ,如果接收到以 FEFF 开头的字节流, 就表明是大端字节序,如果接收到 FFFE, 就表明字节流 是小端字节序UTF-8 没有字节序问题,上述字符只是用来标识它是 UTF-8 文件,而不是用来说明字节顺序的。"零宽度非换行空格" 字符 的 UTF-8 编码是 EF BB BF, 所以如果接收到以 EF BB BF 开头的字节流,就知道这是UTF-8 文件关于文件16进制查看方法,在linux下可以用hexdump $path_to_file命令查,windows下也可以用vim打开后,使用%!xxd 命令,本质上是调用了xxd程序进行转化。windows下也可以用vs code插件,需要安装Hex Editor插件,然后在vscode打开对应文件名页签处右键调用客户端js代码下载函数如下,关键的是在数据前面增加了 FFFE 前缀,浏览器下载后会变更EF BB BF 开头。export function downloadExportUtf8Csv(url, fileName) { request({url: url, method: 'get'}).then(response => { let data = "\ufeff" + response.data let blob = new Blob([data], {type:'text/csv,charset=UTF-8'}) let url = window.URL.createObjectURL(blob) let a = document.createElement("a") a.href = url a.download = fileName a.click() window.URL.revokeObjectURL(url) a.remove() }) }后续在node_module中的客户端库,FileSaver中也有自动转码。auto_bom = function(blob) { // prepend BOM for UTF-8 XML and text/* types (including HTML) // note: your browser will automatically convert UTF-16 U+FEFF to EF BB BF if (/^\s*(?:text\/\S*|application\/xml|\S*\/\S*\+xml)\s*;.*charset\s*=\s*utf-8/i.test(blob.type)) { return new Blob([String.fromCharCode(0xFEFF), blob], {type: blob.type}); } return blob; } FileSaver = function(blob, name, no_auto_bom) { if (!no_auto_bom) { blob = auto_bom(blob); } // ... }
-
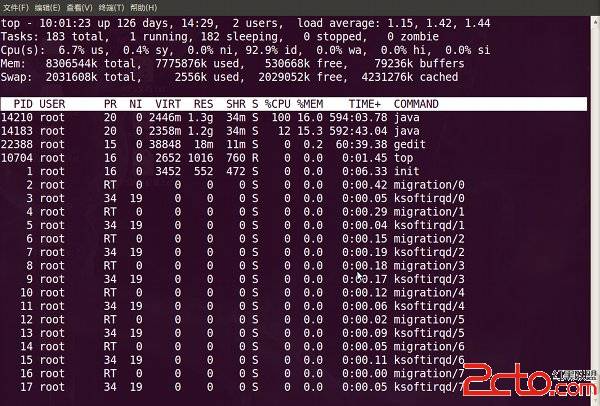
TOP命令 top命令经常用来监控linux的系统状况,比如cpu、内存的使用,程序员基本都知道这个命令,但比较奇怪的是能用好它的人却很少,例如top监控视图中内存数值的含义就有不少的曲解。本文通过一个运行中的WEB服务器的top监控截图,讲述top视图中的各种数据的含义,还包括视图中各进程(任务)的字段的排序。top视图 01top视图简介【top视图 01】是刚进入top的基本视图,我们来结合这个视图讲解各个数据的含义。第一行:10:01:23 当前系统时间126 days, 14:29 系统已经运行了126天14小时29分钟(在这期间没有重启过)2 users 当前有2个用户登录系统load average: 1.15, 1.42, 1.44 load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。 第二行:Tasks 任务(进程),系统现在共有183个进程,其中处于运行中的有1个,182个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。 第三行:cpu状态6.7% us 用户空间占用CPU的百分比。0.4% sy 内核空间占用CPU的百分比。0.0% ni 改变过优先级的进程占用CPU的百分比92.9% id 空闲CPU百分比0.0% wa IO等待占用CPU的百分比0.0% hi 硬中断(Hardware IRQ)占用CPU的百分比0.0% si 软中断(Software Interrupts)占用CPU的百分比在这里CPU的使用比率和windows概念不同,如果你不理解用户空间和内核空间,需要充充电了。 第四行:内存状态8306544k total 物理内存总量(8GB)7775876k used 使用中的内存总量(7.7GB)530668k free 空闲内存总量(530M)79236k buffers 缓存的内存量 (79M) 第五行:swap交换分区2031608k total 交换区总量(2GB)2556k used 使用的交换区总量(2.5M)2029052k free 空闲交换区总量(2GB)4231276k cached 缓冲的交换区总量(4GB) 这里要说明的是不能用windows的内存概念理解这些数据,如果按windows的方式此台服务器危矣:8G的内存总量只剩下530M的可用内存。Linux的内存管理有其特殊性,复杂点需要一本书来说明,这里只是简单说点和我们传统概念(windows)的不同。 第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。如果出于习惯去计算可用内存数,这里有个近似的计算公式: 第四行的free + 第四行的buffers + 第五行的cached,按这个公式此台服务器的可用内存:530668+79236+4231276 = 4.7GB。(free -m命令) 对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。 第六行是空行第七行以下:各进程(任务)的状态监控 **PID 进程idUSER 进程所有者PR 进程优先级NI nice值。负值表示高优先级,正值表示低优先级VIRT(virtual memory usage ) 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RESRES(resident memory uage常驻内存) 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATASHR(shared memory) 共享内存大小,单位kbS 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程%CPU 上次更新到现在的CPU时间占用百分比** %MEM 进程使用的物理内存百分比TIME+ 进程使用的CPU时间总计,单位1/100秒(10毫秒)COMMAND 进程名称(命令名/命令行)关于进程状态:Runnable (R): A process in this state is either executing on the CPU, or it is present on the run queue, ready to be executed.Interruptible sleep (S): Processes in this state are waiting for an event to complete.Uninterruptible sleep (D): In this case, a process is waiting for an I/O operation to complete.Stopped (T): These processes have been stopped by a job control signal (such as by pressing Ctrl+Z) or because they are being traced.Zombie (Z): The kernel maintains various data structures in memory to keep track of processes. A process may create a number of child processes, and they may exit while the parent is still around. However, these data structures must be kept around until the parent obtains the status of the child processes. Such terminated processes whose data structures are still around are called zombies.多U多核CPU监控在top基本视图中,按键盘数字1,可监控每个逻辑CPU的状况:top视图 02观察上图,服务器有16个逻辑CPU,实际上是4个物理CPU。进程字段排序默认进入top时,各进程是按照CPU的占用量来排序的,在【top视图 01】中进程ID为14210的java进程排在第一(cpu占用100%),进程ID为14183的java进程排在第二(cpu占用12%)。可通过键盘指令来改变排序字段,比如想监控哪个进程占用MEM最多,我一般的使用方法如下:1、敲击键盘b(打开/关闭加亮效果),top的视图变化如下top视图 03我们发现进程id为10704的top进程被加亮了,top进程就是视图第二行显示的唯一的运行态(runing)的那个进程,可以通过敲击y键关闭或打开运行态进程的加亮效果。2、敲击键盘x(打开/关闭排序列的加亮效果),top的视图变化如下:top视图 04可以看到,top默认的排序列是%CPU。3、通过shift + >或shift + <可以向右或左改变排序列,下图是按一次shift + >的效果图:top视图 05视图现在已经按照%MEM来排序了。改变进程显示字段1、敲击f键,top进入另一个视图,在这里可以编排基本视图中的显示字段:top视图 06这里列出了所有可在top基本视图中显示的进程字段,有并且标注为大写字母的字段是可显示的,没有并且是小写字母的字段是不显示的。如果要在基本视图中显示CODE和DATA两个字段,可以通过敲击r和s键:CODE (Code size) - 进程的程序码在实体内存占用空间大小,亦叫作 text resident set (TRS)。DATA (Data+Stack size) - 进程占用实体内存中的非程序码部份大小,亦叫作 data resident set (DRS)。top视图 072、回车返回基本视图,可以看到多了CODE和DATA两个字段:top视图 08top命令的补充top命令是Linux上进行系统监控的首选命令,但有时候却达不到我们的要求,比如当前这台服务器,top监控有很大的局限性。这台服务器运行着websphere集群,有两个节点服务,就是【top视图 01】中的老大、老二两个java进程,top命令的监控最小单位是进程,所以看不到我关心的java线程数和客户连接数,而这两个指标是java的web服务非常重要的指标,通常我用ps和netstate两个命令来补充top的不足。 监控java线程数:ps -eLf | grep java | wc -l监控网络客户连接数:netstat -n | grep tcp | grep ${侦听端口} | wc -l上面两个命令,可改动grep的参数,来达到更细致的监控要求。 在Linux系统一切都是文件的思想贯彻指导下,所有进程的运行状态都可以用文件来获取。系统根目录/proc中,每一个数字子目录的名字都是运行中的进程的PID,进入任一个进程目录,可通过其中文件或目录来观察进程的各项运行指标,例如task目录就是用来描述进程中线程的,因此也可以通过下面的方法获取某进程中运行中的线程数量(PID指的是进程ID):ls /proc/PID/task | wc -l在linux中还有一个命令pmap,来输出进程内存的状况,可以用来分析线程堆栈:pmap PID用法 pmap [ -x | -d ] [ -q ] pids... pmap -V选项含义 -x extended Show the extended format. 显示扩展格式 -d device Show the device format. 显示设备格式 -q quiet Do not display some header/footer lines. 不显示头尾行 -V show version Displays version of program. 显示版本扩展格式和设备格式域: Address: start address of map 映像起始地址 Kbytes: size of map in kilobytes 映像大小 RSS: resident set size in kilobytes 驻留集大小 Dirty: dirty pages (both shared and private) in kilobytes 脏页大小 Mode: permissions on map 映像权限: r=read, w=write, x=execute, s=shared, p=private (copy on write) Mapping: file backing the map , or '[ anon ]' for allocated memory, or '[ stack ]' for the program stack. 映像支持文件,[anon]为已分配内存 [stack]为程序堆栈 Offset: offset into the file 文件偏移 Device: device name (major:minor) 设备名top命令使用过程中,还可以使用一些交互的命令来完成其它参数的功能。这些命令是通过快捷键启动的。<空格>:立刻刷新。P:根据CPU使用大小进行排序。M:根据使用内存大小进行排序。T:根据CPU累计时间排序。N:根据PID排序。R:当前排序的反序。H: 切换线程模式查看,可以看到线程级别信息V/v: 以进程父子树形式显示O/o:过滤显示的进程列表,如果在过滤交互输入COMMAND=python表示python关键字命令行的进程,也支持取反操作!COMMAND=python, 支持等式%CPU>3.0,如果输入=号则清空过滤条件q:退出top命令。m:切换显示内存信息的单位有KB、MB、GB。t:切换显示进程和CPU状态信息,以百分比进度条进度展示。c:切换显示命令名称和完整命令行。W:将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。h: 查看按键功能u: 按照用户显示,然后输入用户名,再回车k: 给进程发送SIGTERM信号(可在交互下输入进程号和信号)1: 查看各个CPU使用率, 特别是多核时,常见部分进程占用超过100%, 最高可以达到100*核数